
Solving Advent of Code in Under a Second
February 3, 2019
The Advent of Code is a programming competition organized by Eric Wastl every December. It's an advent calendar where every day a new two-part puzzle is released.
I used the competition as a way to help teach myself Rust. I also gave myself a goal of solving all puzzles in under a second.
I wrote two posts about this experience. This post is (mostly) language agnostic and focuses on the puzzles and my solutions.
If you're interested in my Rust specific experiences please give my other post a read.
Learning Rust via Advent of Code.
Source
Source code is available in an easy-to-view web format. You can also download the full project if you'd like to run it for yourself.
Performance
Every AoC puzzle can be solved in under 15 seconds in a dynamic language on slow hardware. I'm using a compiled language on a high-end i7-8700k desktop.
I set a goal to run in under one second total on a single thread. How'd I do?
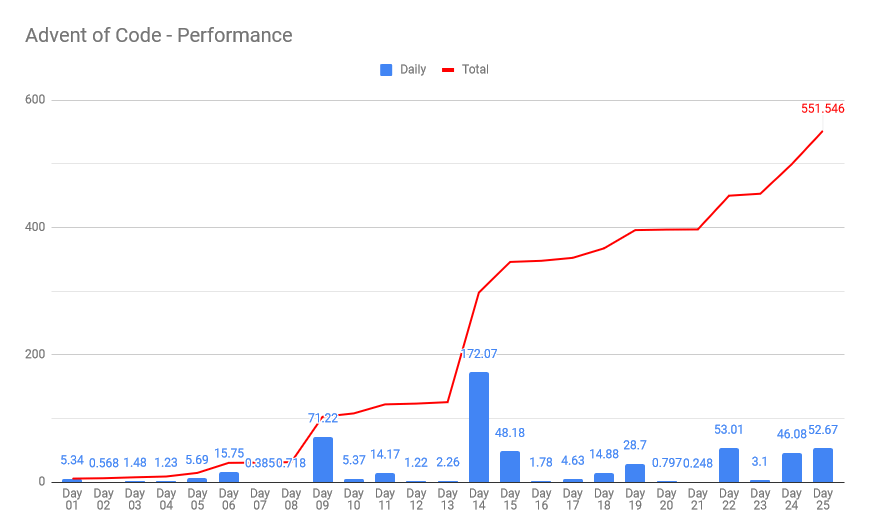
With some extra effort I clock in at about 550 milliseconds. Success!
I'm pretty happy with my solutions. There's plenty of room for improvement. But I met my goal and then some.
Reddit user askalski posted their hyper-optimized SIMD solutions on Reddit and GitHub. It runs in a mindblowing 41 milliseconds.
Talk about an ego buster. His solution set is more than 10x faster than mine!
I can't claim the speed crown. I can briefly talk about my approach and experience. This post will also serve as a mini-review of AoC.
Goals
I had a few goals. Top priority was to solve all puzzles in under a second on a single thread.
My secondary goal was to write code that could handle inputs for any user. Every AoC participant gets their own input. Some solutions are overly specialized and don't work for every input.
I went a half-step further and wanted to make sure I could handle plausible inputs. For example I never optimized a solution to take advantage of an input grid being 32x32. I won't claim to handle all inputs. But my solutions aim to be robust.
Basic Performance
For Advent of Code if the only thing you do is use vectors and perform operations in-place you'll have fast code.
Many user post solutions that take 5+ seconds for a single puzzle. Sometimes the culprit is an inefficient n^2 algorithm. More often it is expensive string operations, array splits and splices, or using a linked list.
I won't say that linked lists are evil. But I might be thinking it. Modern processors are mind blowingly fast. Memory speed has not kept up.
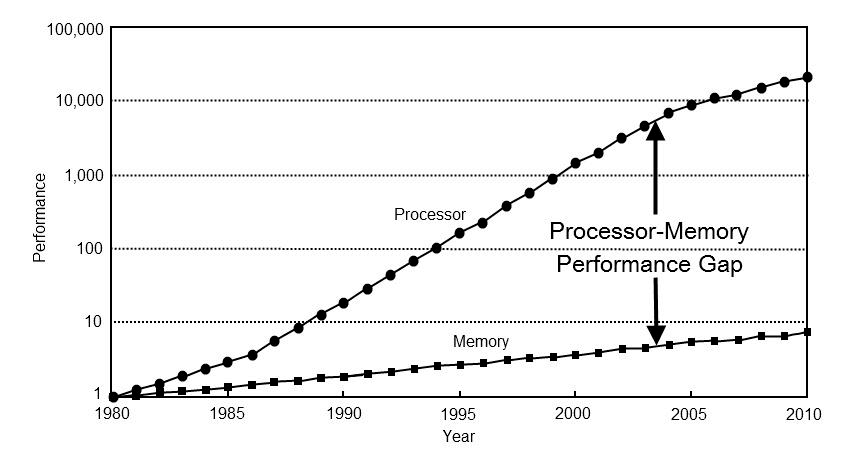
Memory access is my bottleneck more often than not. Design code for cache coherency. Use a vector until you have a compelling reason not to.
HashMaps
I like HashMaps and HashSets. They have beautiful semantics. They work when you don't know your bounds. They're also super slow.
At some point I saved over 100ms by converting a handful of HashMaps and HashSets to simple Vectors. My structs for handling x,y coordinates have fn get_index(width: i32) for getting an array index. This only works if you know your bounds.
I'd like to write a helper that replaces a HashMap with a tiled vector system. That would greatly improve my day18 solution; which involves pathfinding through a deep cave.
My final code saves ~50ms by using hashbrown::HashMap over std::collections::HashMap. Hashbrown is a drop-in replacement with identical API to std. An 8.3% improvement for two minutes of work is pretty nice!
Puzzles
I'm not going to go through every puzzle. I'll call out a handful that I think are interesting for one reason or another. None of my solutions aren't unique. I am proud of the visualization I put together for Day 23.
Day 6
This one is interesting in that the author did not force users to handle edge cases.
The problem is to take a series of 2d coordinates and find the largest non-infinite area. It reminded me of voronoi diagrams.

Manhattan Distance Voronoi Diagram via Wikipedia
The puzzle inputs allow solvers to ignore cells which touch the border. I think the puzzle author should have been mean. He should have forced us to find finite areas that cross the input bounds.
Day 9
This is the first puzzle that requires explicit attention to performance.
The problem defines a funny Elf game. Players build a circle of marbles. Each turn marbles are inserted or removed somewhere in the circle. It's fully deterministic so you "just" have to simulate the rules of the game.
Part one requires ~70,000 insert and remove operations. Computers are fast enough that even a naive vector can get the job done.
Part two is the exact same thing, but with 100x more operations. Over 7 million insertions and deletions on a list with millions of elements.
One option is a doubly-linked list. This will work, but may be quite slow. Chasing pointers kills performance. Storing 64-bit pointers is a waste of precious cache space. My C++ std::list implementation takes over 450 milliseconds.
My Rust solution is a "linked-list" made from a vector of structs that store an index for next/prev. Marbles are generally adjacent so this is much better.
struct Marble { prev: u32, next: u32, } struct MarbleCircle { marbles: Vec<Marble>, } pub fn insert_after(&mut self, idx: usize, marble: usize) { let old_next = self.marbles[idx].next; self.marbles[idx].next = marble as u32; self.marbles[marble].prev = idx as u32; self.marbles[marble].next = old_next as u32; self.marbles[old_next as usize].prev = marble as u32; } pub fn move_clockwise(&self, marble: usize, count: usize) -> usize { let mut result = marble; for _ in 0..count { result = self.marbles[result].next as usize; } result }
There's a few more helpers I excluded for brevity.
Some Redditors calculated their naive Python solution would take upwards of 5 hours to complete. This version runs in 70ms.
Day 10
This puzzle left me somewhat unsatisfied.
Input: List of 2D star positions and 2D velocities
Problem 1: What do stars spell when, ahem, the stars align?
Problem 2: How long did it take?
The trick to this is to wait for the bounding box to be as small as possible. I printed the output and eyeballed what it spelt.
Day 10, Problem 1:
######..#....#..#####....####...#####...#####...#....#..#####.
#.......##...#..#....#..#....#..#....#..#....#..#....#..#....#
#.......##...#..#....#..#.......#....#..#....#..#....#..#....#
#.......#.#..#..#....#..#.......#....#..#....#..#....#..#....#
#####...#.#..#..#####...#.......#####...#####...######..#####.
#.......#..#.#..#..#....#..###..#.......#....#..#....#..#..#..
#.......#..#.#..#...#...#....#..#.......#....#..#....#..#...#.
#.......#...##..#...#...#....#..#.......#....#..#....#..#...#.
#.......#...##..#....#..#...##..#.......#....#..#....#..#....#
#.......#....#..#....#...###.#..#.......#####...#....#..#....#
I don't love this puzzle. There's no guarantee the smallest bounds spells something. It requires a manual translatoin step. Glyph lookup is possible, but only after manually defining glyphs. It feels like cheating either way. :(
At least one person implemented an OCR solution. I also like the TensorFlow gradient descent solution. AoC participants are delightfully creative.
Day 11
I love this puzzle and learned something new.
Input: Param used to generate a 300x300 grid of signed integers.
Problem 1: What 3x3 sub-grid has the largest sum?
Problem 2: What NxN sub-grid has the largest sum? Where N ∈ [0,300]
There's a very naive way to solve this.
let mut best_sum = 0; for n in 1..=300 { for row in 0..300 - n { for col in 0..300 - n { let mut sum = 0; for r in r..r+n { for c in c..c+n { sum += grid[r][c]; } } best_sum = max(best_sum, sum); } } }
This works. It's roughly O(N^5), but it works. On my machine this took about 1.3 seconds. Given my goal of running under 1 second total this was a major problem!
I spent some time trying to make this run faster. My progress was slow and incremental. One of my favorite things about Advent of Code is the subreddit. There is a daily solutions thread where people post their solutions in a wide range of languages.
From that thread I learned about a new thing. The summed area table. I'd never heard of this data structure before. It's super simple. My solution time plummeted from over 1 second to 14 milliseconds. Huzzah!
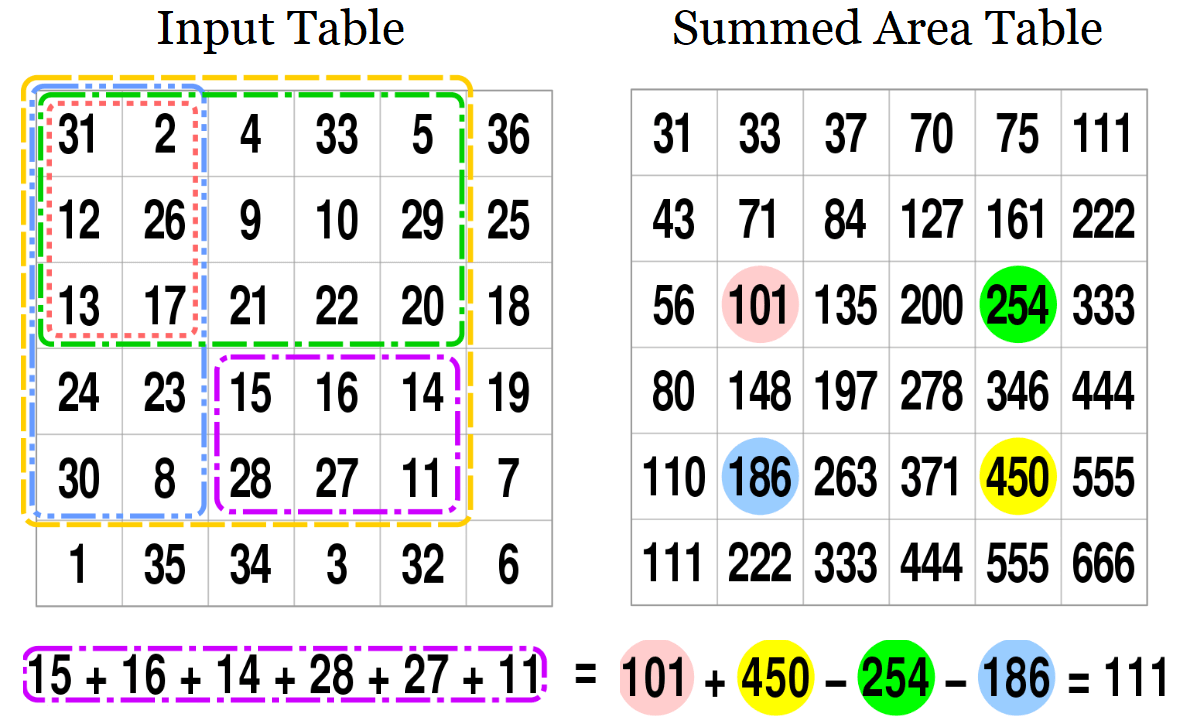
Source: Wikipedia
Day 12
This puzzle followed a pattern that appeared several times.
Part one is to implement some abstract set of rules. Part two requires running those rules for so many iterations it can't possibly be simulated. The trick is to detect a pattern and extrapolate the final state.
This particular puzzle involves an infinite line of pots. Each generation a pot may or may not contain a plant based on the previous state.
If you watch the video you'll clearly see the end state. A fixed pattern that shifts can be easily detected in code.
Day 14
My slowest function. It takes a whopping 172 milliseconds. Which is optimized down from 298ms!
This is another puzzle with abstract, arbitrary rules. In this case you have a list of integers and two positions in the list. Each iteration one or two new digits is added and the positions increment, possibly wrapping. My input involves growing the list to over 20 million integers.
My first optimization was to unroll a loop over a fixed array of size two. I was shocked the compiler didn't do this. Weird and disappointing. This saved, much to my surprise, ~15 milliseconds.
I cached index and recipe sequences. It's heavy handed and I don't love it. It saved another ~40ms.
Converting checked array indexing into unsafe unchecked accesses saved 10ms. This was a savings on other problems as well.
Changing indices from usize to u32 saved 15ms.
askalski's posted details on his solution in a Reddit thread titled Breaking the 1 billion recipes per second barrier. It runs in 19ms. 😲
Day 15
This puzzle was brutal. It caused a lot of people to stop trying.
It isn't a particularly hard puzzle. In some ways it's not even interesting. The problem is to simulate a battle between elves and goblins with nuanced rules. Most of the work is to perfectly follow those rules. Which aren't always clear.
This puzzle does require pathfinding. Which is easily solved with a simple breadth first search.
Optimization improved my solution from 110ms to 48ms.
- 20ms saved by replacing
BinaryHeapwithVecDeque - 23ms saved by replacing
HashMapwithVec<bool> - 10ms saved by replacing a needless sort with
min_by_key
I tried the bitvec crate. Much to my surprise it made my code slower!
Day 16
This puzzle is interesting in that it serves as a baseline for two more puzzles later.
The task is mostly to implement a super simple set of 16 assembly instructions (ElfCode).
enum OpCode { addr, // rC = rA + rB addi, // rC = rA + b mulr, // rC = rA * rB muli, // rC = rA * b banr, // rC = rA & rB bani, // rC = rA & b borr, // rC = rA | rB bori, // rC = rA | b setr, // rC = rA seti, // rC = a gtir, // rC = a > rB ? 1 : 0 gtri, // rC = rA > b ? 1 : 0 gtrr, // rC = rA > rB ? 1 : 0 eqir, // rC = a == rB ? 1 : 0 eqri, // rC = rA == b ? 1 : 0 eqrr, // rC = rA == rB ? 1 : 0 }
Day 17
I spent 30 minutes debugging my final answer. I couldn't figure out why I was slightly off by four. The answer is because I couldn't read.
...ignore tiles with a y coordinate smaller than the smallest y coordinate in your scan data
Advent of Code has a lot of little rules like this. AoC is a competition that has a leaderboard for solving puzzles the fastest. Part of that DNA is purposefully hard to understand instructions. Part of the problem solving is piecing it together.
I'm not used to this. Expressing complex thoughts with clarity is a big part of my daily job! I spent several cumulative hours debugging issuing that amounted to errors in reading comprehension. It didn't help that I solved puzzles around midnight.
Day 18
Basically Conway's Game of Life. Part two is the curiously recurring pattern of cycle detection.
Day 19
An unsatisfying ElfCode problem. This one takes the asm instructions from Day 16 and adds an instruction pointer.
Part two will basically never finish running if you just let it run. Maybe it'd finish in a few hours. I don't know.
The common solution was to hand annotate the asm to figure out what it's doing. It's very, very slowly computing the sum of factors of an 8-digit number. My final answer was produced entirely by hand.
Reading and writing assembly is a skill every programmer should have. I should play more Zachtronics games. ElfCode puzzles did not help me learn Rust so I put them off until the end.
Day 20
This puzzle involves parsing a regex-like structure to build a map of rooms and doors. All of the hard work is in parsing the input stream.
My solution builds the map then answers the puzzle questions. It'd be faster to do in one pass.
If you look at the video it's a maze! You can even tell what kind of algorithm was used to generate the input.
Mazes are fun. You can read about all kinds of fun maze algorithms here and here.
Day 21
Another unsatisfying ElfCode puzzle.
Part one I quickly answered by tracing the problem by hand. The answer is apparent almost immediately.
Part two took me forever. First, I hand annotated the mildly obfuscated asm to understand what it was doing.
// #ip 2 00 seti 123 0 3 // reg[3] = 123 01 bani 3 456 3 // reg[3] |= 456 02 eqri 3 72 3 // reg[3] == 72 { goto 5 } else { goto 4 } 03 addr 3 2 2 04 seti 0 0 2 // goto 1 05 seti 0 0 3 // reg[3] = 0 06 bori 3 65536 4 // reg[4] = reg[3] | 65536 07 seti 10649702 3 3 // reg[3] = 10649702 08 bani 4 255 5 // reg[5] = reg[4] & 255 09 addr 3 5 3 // reg[3] += reg[5] 10 bani 3 16777215 3 // reg[3] &= 16777215 11 muli 3 65899 3 // reg[3] *= 65899 12 bani 3 16777215 3 // reg[3] &= 16777215 13 gtir 256 4 5 // if 256 > reg[4] { goto 16 } else { goto 15} 14 addr 5 2 2 15 addi 2 1 2 // goto 17 16 seti 27 7 2 // goto 28 17 seti 0 6 5 // reg[5] = 0 18 addi 5 1 1 // reg[1] = reg[5] + 1 19 muli 1 256 1 // reg[1] *= 256 20 gtrr 1 4 1 // if reg[1] > reg[4] { goto 23 } else { goto 22 } 21 addr 1 2 2 22 addi 2 1 2 // goto 24 23 seti 25 9 2 // goto 26 24 addi 5 1 5 // reg[5] += 1 25 seti 17 9 2 // goto 18 26 setr 5 7 4 // reg[4] = reg[5] 27 seti 7 1 2 // goto 8 28 eqrr 3 0 5 // if reg[3] == reg[0] { halt } else { goto 6 } 29 addr 5 2 2 30 seti 5 4 2
I translated that to Rust and added an end condition check. It took 180ms.
Then I realized part of the code was merely dividing by 256 in a hilariously slow way. Converting that to a straight divide-by-256 let the program finish in 1ms.
pub fn run() -> String { let mut result = String::with_capacity(128); // Part 1 solved by hand writeln!(&mut result, "Day 21, Problem 1 - [1797184]").unwrap(); // Part 2 let mut encountered: HashSet<usize> = HashSet::default(); let mut last = 0; // Prelude let mut r1: usize = 0; let mut r4: usize = 0; let mut r5; let mut skip_to_eight = false; loop { if !skip_to_eight { r4 = r1 | 65536; // 6 r1 = 3_798_839; // 7 } skip_to_eight = false; r5 = r4 & 255; // 8 r1 += r5; // 9 r1 &= 16_777_215; // 10 r1 *= 65899; // 11 r1 &= 16_777_215; // 12 if 256 > r4 { let v = r1; let inserted = encountered.insert(v); if !inserted { // 11011493 writeln!(&mut result, "Day 21, Problem 2 - [{}]", last).unwrap(); return result; } last = v; continue; // 30 } r4 /= 256; skip_to_eight = true; } }
Day 22
This puzzle was super fun. Part one involves building a cave map according to, as usual, some arbitrary rules. Then you have to pathfind through it.
Up until this puzzle I solved all pathfinding problems with a basic breadth first search. This one requires Dijkstra's Algorith or A*. This puzzle also has some very subtle rules, such as needing to end with a torch.
I personally think a lot of solutions cheated on this one. They made certain assumptions about how far away from the target they needed to go.
My initial solution ran in 258ms. My final version takes 53ms.
I saved 55ms by moving HashSet intersection to precomputed itersection. That made me sad. I like the ergonomics of HashSet.intersect. Another 7ms came from converting checked array accesses into unsafe unchecked accesses.
I saved a whopping 50ms by converting std::collections::HashMap to FnvHashMap. Switching to hashbrown saved another ~30 ms.
Day 23
This is the only solution I'm particularly proud of. None of my solutions are unique or original. Not even this one. In fact my solution is the same as what the puzzle author used to make it!
For whatever reason reddit really struggled this one. Many solutions are lucky and don't handle common user inputs. Particularly clever users solved it with the shockingly powerful Z3 SMT solver. I need to learn more about this tool.
Input: ~1000 nanobots with 3d position and radius
Problem: Find the coordinate covered by the MOST nanobots. Closest to origin breaks ties.
All math is in integer coordinates and distances are manhattan distance. This technically makes the nanobot shape an octahedron. I chose to think about and visualize the problem using spheres.
This is a surprisingly tricky problem. The goal is to find the 1x1x1 point covered by the most nanobots. Complicating matters is the scale of the problem. Bots have a radius on the order of tens of millions. Their positions have a range in the hundreds of millions. A brute force solution would check on the approximate order of 2^90 (1 octillion) points.
Two-Dimensional
Let's think about the problem in 2D for a minute. Imagine a piece of paper covered in circles. One simple option might be a binary search.
Cut the space in half and see which half has the most nanobots. Take that half and subdivide it into two smaller halves. Rinse and repeat until you have an answer.
There's a problem. It's demonstrated by my hand-drawn binary search.
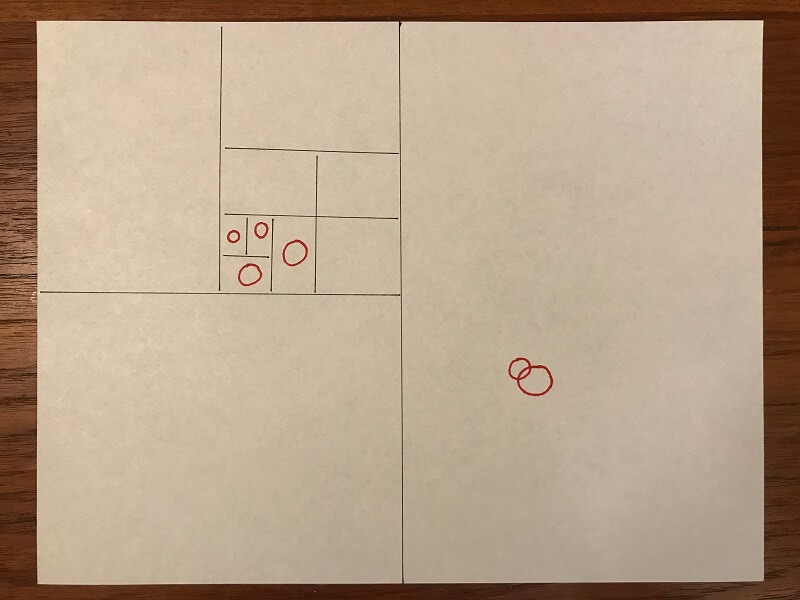
There are two clusters of red nanobots. Four in the upper-left and two in the lower-right. A naive binary search would divide the space in half and pick the half with four total bots. It would continue to have four bots for several subdivision. Until it eventually discovers none of the bots overlap at all. Meanwhile the half that had only two nanobots contains an overlap and thus our answer.
The fix is a traversal order I think is pretty neat. It's neither breadth-first nor depth-first. I'd call it potential first.
The traversal order needs to drill down, but then back pop-up. Then drill a little deeper, and pop-up again. Each step it needs to subdivide the node that has the most potential.
Here's some pseudocode for what that might look like:
best_leaf = None; // best 1x1x1 node nodes.push(root); while !nodes.is_empty() { let node = nodes.pop(); // ignore any node worse than best leaf if best_leaf && best_leaf.num_bots > node.num_bots { continue; } // leaves are 1x1x1 if node.is_leaf() { // Found leaf. Check if it's best. if best_leaf.is_none() || node.num_bots > best_leaf.num_bots || node.distance_from(origin) < best_leaf.distance_from(origin) { best_leaf = Some(node); } } else { // create and add children let children = node.subdivide(); for child in children { nodes.push(child); } // sort nodes by: num_bots THEN larger_volume THEN closer_to_origin nodes.sort_by(|a,b| { a.num_bots.cmp(b.num_bots) .then(a.volume().cmp(b.volume())) .then(b.distance_from(origin).cmp(a.distance_from(origin))); }); } }
Octree
For my solution I used an Octree. This is a super common data structure in game development.
I put together a neat little visualization in Unity3D. It's my attempt to render the Octree node traversal order.
My solution takes just 3ms to run. It processes only 737 Octree nodes. The answer is 29 levels deep.
Build Flags
One of my more surprising optimizations was changing a pair of build flags.
Rust's release configuration doesn't enable link-time optimization (LTO). This is pretty reasonable. While reading documentation I came across a funny comment.
codegen-units = 16 // if > 1 enables parallel code generation which improves // compile times, but prevents some optimizations.
That's interesting!
Settings LTO=true and codegen-units=1 saved 40 milliseconds. A 6.7% speedup for a slightly longer compile time. I'll take it!
Of the 40ms saved a full 26ms came from Day18, the Conways Game of Life puzzle. I'm curious what got optimized.
What's even more interesting is that setting just LTO=true or just codegen-units=1 results in a ~30ms speedup. Enabling both saves only another ~10ms. There's a curious amount of overlap!
2019 Wishlist
I thoroughly enjoyed my time solving Advent of Code puzzles. It was fun and educational. There are a few things I'd love to see in 2019
Third Star - Robustness
I'd love to see a third star for robustness.
A lot of problems have really interesting edge cases. They aren't always tested. For example day6 where assumptions of infiniteness can be made. Or day22 where the cave is tall and narrow. Askalski notes his day 20 solution "exploits how the input was generated".
I think it'd be super fun to have a third star that tests those edge cases. This forces code to be robust and not make too many assumptions.
Fourth Star - Performance Competition
This is a bit pie in the sky. It would be super awesome to have official competention for performance.
The simplest version is to provide input that takes ~30 seconds to solve with a "good" solution. This may require two tiers for dynamic and compiled languages.
The elaborate version requires servers, language support, and user submitted code. This would be a lot of work and cost money. But it'd be so cool! I'd happily kick in a few bucks.
Final Thoughts
I had a ton of fun with Advent of Code. I learned a lot about Rust. I learned some new algorithms. I wrote some reasonably quick code. I made some neat videos.
Thanks for reading.