
Using Rust to Delete Gitignored Cruft
June 13, 2020
I have a problem - my SSD is always running out of space. Part of the problem is build system cruft. Over time I accumulate repos and projects full of temp files and build artifacts. These files are sprinkled across many folders which makes them difficult to identify and delete.
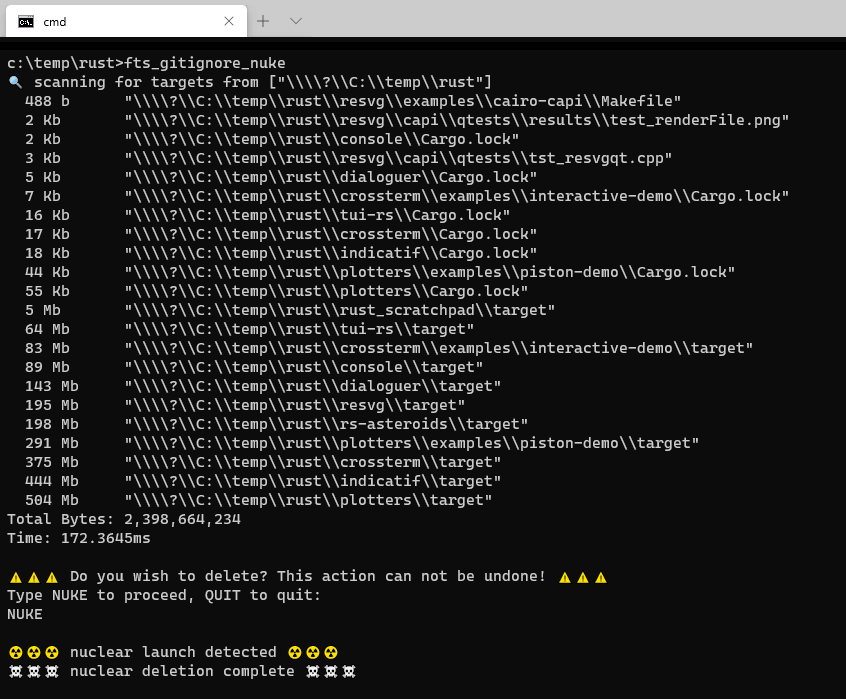
To help solve my problem I wrote a tool - fts_gitignore_nuke. The goal of this tool is to identify files masked by .gitignore and delete them.
You may be asking yourself, why not just run something like git clean -dX? That works, but only sometimes. fts_gitignore_nuke is motivated by a set of requirements.
- Delete files across many source repos at once.
- Delete files inside Git, Mercurial, and Perforce repos.
- Delete files within a monorepo.
- Support Windows, macOS, and Linux.
There's no existing tool that supports all my requirements. At home I have dozens of Git repos. At work I have a Mercurial monorepo plus Perforce. I want one tool to rule them all. One simple command line invocation that works across all of my personal use cases.
This tool didn't exist, so I made it. I'm sharing this tool and post because I think it's a useful tool and a maybe interesting read.
tldr;
fts_gitignore_nuke is a command line tool that identifies paths masked by .gitignore files and allows you to delete them.
No file will EVER be deleted without explicit user input. After scanning for targets the user MUST explicitly type "NUKE" for anything to be deleted.
- Source Code: GitHub
- Installation:
cargo install fts_gitignore_nuke.
Basic Algorithm
- Initialize
.gitignorestack. - Recursively iterate directories from current/specified dir.
- Push new
.gitignorefiles on the stack. - Add ignored paths to a list.
- Sort and display ignored paths to user.
- Nuke paths IFF explicitly invoked by user.
All together it's about 400 lines of custom code. That excludes libraries which do some heavy lifting.
Using Rust
My tool is written in Rust. Why? A few reasons.
- Robust ecosystem.
- Easy crossplatform support.
- Rust code is fun to write!
I use the ignore crate which is part of the wildly popular ripgrep tool. Ripgrep uses ignore to iterate a file tree and only return non-ignored files. My use case is similar, but flipped. I want to walk a full file tree, but only process ignored paths!
I also use cactus which is "cactus stack" or parent-pointer tree. This allows me to build an immutable thread-safe "stack" of .gitignore files.
The first working version of my code looked *roughly* like this.
// Build .gitignore stack (not shown) let mut ignore_tip = Cactus::new(); // List of all ignored paths let mut ignored_paths : Vec<std::path::PathBuf> = Default::default(); // Queue of paths to consider let mut queue : std::collections::VecDeque<(Cactus<Gitignore>, std::path::PathBuf)> = Default::default(); queue.push_back((ignore_tip, starting_dir)); // Process all paths while !queue.is_empty() { let (mut ignore_tip, entry) = queue.pop_front().unwrap(); // Append new .gitignore files to ignore stack let ignore_path = entry.join(".gitignore"); if ignore_path.exists() { let mut ignore_builder = GitignoreBuilder::new(&path); ignore_builder.add(ignore_path); if let Ok(ignore) = ignore_builder.build() { ignore_tip = ignore_tip.child(ignore); } } // Process each child in directory for child in fs::read_dir(entry)? { let child_path = child?.path(); let child_meta = match std::fs::metadata(&child_path)?; let is_ignored = ignore_tip.iter() .map(|i| i.matched(&child_path, true)) .any(|m| m.is_ignore()); if is_ignored { ignored_paths.push(child_path); } else if child_meta.is_dir() { queue.push_back((ignore_tip.clone(), child_path)); } } } // Compute dirsize and sort ignored paths let mut final_ignore_paths : Vec<_> = ignored_paths.into_iter() .map(|dir| (dir_size(dir.clone()), dir)) // compute directory/file size .filter_map(|(bytes, dir)| if let Ok(bytes) = bytes { Some((bytes, dir)) } else { None }) // ignore dir_size(...) errors .filter(|(bytes, _)| *bytes >= min_filesize_in_bytes) // ignore paths smaller than min size .sorted_by_key(|kvp| kvp.0) // sort by size .collect(); // Ask user if they want to NUKE. If yes then: for (_, path) in final_ignore_paths { if fs::metadata(&path)?.is_file() { fs::remove_file(&path)?; } else { fs::remove_dir_all(&path)?; } }
I ommitted some details, simplified error handling, and this version has bugs. But this is a fair approximation of my first pass single-threaded version.
Fearless Concurrency
One of Rust's major goals is fearless concurrency. This means programmers should be able to write parallel code without fear of bugs.
fts_gitignore_nuke is full of dependent I/O operations. But there is clear opportunity for parallelization. I achieved a 4x speed increase on my 6-core i7 8700k desktop when running with 6 threads. That isn't a perfectly linear increase in performance, but that ain't bad.
Parallelization is achieved primarily through a work-stealing scheduler.
Work-Stealing Scheduler
The crossbeam-deque crate provides concurrent data structures for building a work-stealing scheduler. The concept of any work-stealing system is to get a new task as follows:
- Get next task from local worker queue.
- Get set of tasks from global queue.
- Steal set of tasks from another worker.
crossbeam-deque documentation provides this implementation of a work-stealing system:
fn find_task<T>( local: &Worker<T>, global: &Injector<T>, stealers: &[Stealer<T>], ) -> Option<T> { // Pop a task from the local queue, if not empty. local.pop().or_else(|| { // Otherwise, we need to look for a task elsewhere. iter::repeat_with(|| { // Try stealing a batch of tasks from the global queue. global.steal_batch_and_pop(local) // Or try stealing a task from one of the other threads. .or_else(|| stealers.iter().map(|s| s.steal()).collect()) }) // Loop while no task was stolen and any steal operation needs to be retried. .find(|s| !s.is_retry()) // Extract the stolen task, if there is one. .and_then(|s| s.success()) }) }
fts_gitignore_nuke has two recursive operations we want to parallelize.
- Find ignored paths.
- Compute size of ignored paths.
Because directory trees are not balanced we don't want a single subtree to be "owned" by a single thread. We want to distribute work to keep N threads busy.
Leveraging crossbeam-deque was a little harder than I expected. I won't pretend that I did a great job. But I did put together something that works. And, astonishingly, I ran into exactly zero run-time bugs.
For simplicity I chose to create and tear down worker threads for each of my two operations. Here's what that looks like.
pub fn run_recursive_job<IN,OUT,JOB>(initial: Vec<IN>, job: JOB, num_workers: usize) -> Vec<OUT> where IN: Send, OUT: Send, JOB: Fn(IN, &Worker<IN>) -> Option<OUT> + Clone + Send, { // Create crossbeam_deque injector/worker/stealers let injector = Injector::new(); let workers : Vec<_> = (0..num_workers).map(|_| Worker::new_lifo()).collect(); let stealers : Vec<_> = workers.iter().map(|w| w.stealer()).collect(); let active_counter = ActiveCounter::new(); // Seed injector with initial data for item in initial.into_iter() { injector.push(item); } // Create single scope to contain all workers let result : Vec<OUT> = crossbeam_utils::thread::scope(|scope| { // Container for all workers let mut worker_scopes : Vec<_> = Default::default(); // Create each worker for worker in workers.into_iter() { // Make copy of data so we can move clones or references into closure let injector_borrow = &injector; let stealers_copy = stealers.clone(); let job_copy = job.clone(); let mut counter_copy = active_counter.clone(); // Create scope for single worker let s = scope.spawn(move |_| { // results of this worker let mut worker_results : Vec<_> = Default::default(); // backoff spinner for sleeping let backoff = crossbeam_utils::Backoff::new(); // Loop until all workers idle loop { { // look for work let _ = counter_copy.take_token(); while let Some(item) = find_task(&worker, injector_borrow, &stealers_copy) { backoff.reset(); // do work if let Some(result) = job_copy(item, &worker) { worker_results.push(result); } } } // no work, check if all workers are idle if counter_copy.is_zero() { break; } // sleep backoff.snooze(); } // Results for this worker worker_results }); worker_scopes.push(s); } // run all workers to completion and combine their results worker_scopes.into_iter() .filter_map(|s| s.join().ok()) .flatten() .collect() }).unwrap(); result }
Let's look a little closer. Here's the function again.
pub fn run_recursive_job<IN,OUT,JOB>(initial: Vec<IN>, job: JOB, num_workers: usize) -> Vec<OUT> where IN: Send, OUT: Send, JOB: Fn(IN, &Worker<IN>) -> Option<OUT> + Clone + Send, { // Do stuff }
This function is going to invoke job on each element of initial: Vec. In my case IN is std::path::PathBuf. That job also takes a &Worker param allowing the job to push additional data into the job queue. The job returns an Option<OUT> where OUT is Vec<std::path::PathBuf>.
In other words, a job processes a single path, returns Option<Vec<PathBuf>> containing any ignored child paths (files or directories), and pushes non-ignored child directories into the local work queue. run_recursive_job then returns a single Vec<PathBuf> containing all the ignored paths. A simple counter system is used to determine when all workers are finished.
In this scenario the global injector does almost nothing. The initial directory is fed into it, but afterwards it's unused. I'm ok with this.
I'm not sharing this because I think my implementation is amazing. I'm not an expert at this. In fact, that's what I think makes it so cool! Despite my non-expertise I was able to leverage Rust and community libraries to assemble a "good enough" parallel architecture that is both safe and performant.
Fearless concurrency? Yeah, I'd say so!
Design Problems
Designing the behavior of fts_gitignore_nuke was more difficult than I expected. Once I had something working on my machine I had a friend run it. Unfortunately it wanted to delete his entire project folder. Yikes!
I'm primarily a Windows user. My friend was on Linux. He had a .gitignore in /User/foo/ that explicitly ignored everything. He used this to store his dotfiles which were added with --force. At the time my tool included all parent gitignores. Oops!
My current solution only includes parent ignores if --root is specified. This works better in the default case, but still works with monorepos.
Unpopular/Ignorant Opinion: git add foo --force is a bad idea. It means no tool can determine a file's status without running a git command. That sucks for a lot of reasons. --force should at least update a .gitignore file. Grumble grumble.
There may be other use cases I don't support. I haven't considered symlinks one way or another. This is a surprisingly complex and nuanced design space. If anyone has a scenario that doesn't work file an issue on GitHub! I'm happy to extend fts_gitignore_nuke if it's useful to people.
Final Thoughts
My computers, both work and home, constantly run out of SSD space. I wrote a tool called fts_gitignore_nuke to help reclaim precious SSD gigabytes. It's written in Rust which makes it fast, safe, and cross-platform. I think my tool will be useful to a few folks. And I hope this blog post was informative to a few more.
Thanks for reading.
- Source Code: GitHub
- Install:
cargo install fts_gitignore_nuke
Bonus! Concurrent data structures.
crossbeam_deque provides highly optimized structures for building concurrent systems. A very naive alternative is Arc<Mutex<Vec<T>>>. This is a Vec wrapped in a Mutex that is atomically ref counted. Each push/pop would require locking the Mutex. 😱
I was curious so I swapped out crossbeam_deque with such a custom, naive system. The end result was... identical performance. This makes sense! Most my program time is spent on IO or running .gitignore string comparisons. Time spent locking/unlocking a Mutex is miniscule.
I wouldn't recommend shipping the naive approach. But as a learning exercise it's worth going through for sure.
Bonus! Keeping select local files.
After initial publication a reader responded with some thoughts. They loved the tool, but didn't want to nuke everything not in Git. They had some private keys and rendered video files that were hidden by .gitignore, but they didn't want to delete.
This reader was kind enough to offer up both a proposal and pull request. fts_gitignore_nuke now loads both .gitignore and .gitnuke files. The .gitnuke files are optional ignore files that take higher priority than all than all .gitignore files. Typical usage is to whitelist paths to keep.
If you have another use that isn't supported please let me know and I'm happy to work with you.