Benchmarking Malloc with Doom 3
June 3rd, 2022
This blog post began the same way as many of my posts. I nerd sniped myself.
I recently read about a new audio library for games. It repeated a claim that is conventional wisdom in the audio programming world – "you can't allocate or deallocate memory on the audio thread". That's a very strong statement, and I'm not sure it's correct.
Lately I've been doing quite a bit of audio and audio-like programming. My code is efficient and does pre-allocate quite a bit. However it uses both malloc and mutex. It also happens to run great and glitch free!
Here's my question: what is the worst-case performance for malloc on a modern machine in practice?
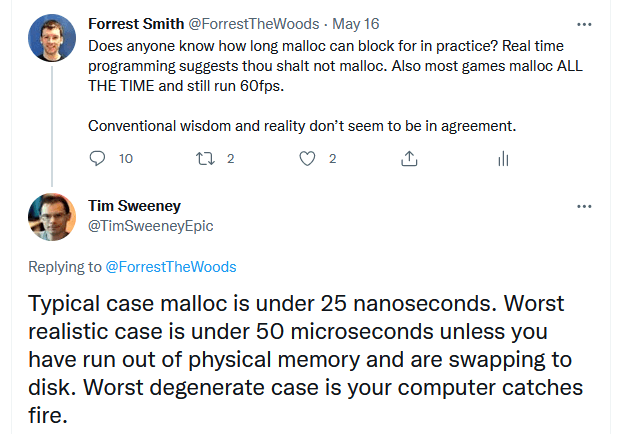
Source: Twitter
Framing the Question
Answering performance questions is hard. The boring answer is always the same – it depends!
How big is your allocation? What is your program's allocation pattern? Is it heavily multi-threaded? Are you a long lived server or medium lived game? It always depends.
Allocating memory isn't free. Time spent on complex systems full of error prone lockless programming isn't free either. My spidey sense suggests malloc is cheaper than people realize.
For today I'm focused on games. Modern games run between 60 and 144 frames per second. One frame at 144Hz is about 7 milliseconds. That's not very many milliseconds! Except I know most games hit the allocator hard. Worst case in theory sets my computer on fire. What is it in practice?
My goal isn't to come up with a singular, definitive answer. I'm a big fan of napkin math. I want a ballpark guideline of when malloc may cause me to miss my target framerate.
Creating a Journal
My first attempt at a benchmark involved allocating and freeing blocks of random size. Twitter friends correctly scolded me and said that's not good enough. I need real data with real allocation patterns and sizes.
The goal is to create a "journal" of memory operations. It should record malloc and free operations with their inputs and outputs. Then the journal can be replayed with different allocators to compare performance.
Unfortunately I don't have a suitable personal project for generating this journal. I did a quick search for open source games and the choice was obvious – Doom 3!
It took some time to find a Doom 3 project that had a "just works" Visual Studio project. Eventually I found RBDOOM-3-BFG which only took a little effort to get running.
All memory allocations go through Mem_Alloc16 and Mem_Free16 functions defined in Heap.cpp. Modifying this was trivial. I started with the simplest possible thing and wrote every allocation to disk via std::fwrite. It runs a solid 60fps even in debug mode. Ship it!
void* fts_allocator::allocInternal(const size_t size) { auto allocRelativeTime = (Clock::now() - _timeBegin); // Perform actual malloc auto ptr = _aligned_malloc(size, 16); // AllocEntry = a allocSize ptr threadId timestamp std::array<char, 256> buf; int len = std::snprintf( buf.data(), buf.size(), "a %lld %p %lu %lld\n", size, ptr, GetCurrentThreadId(), allocRelTime.count()); std::fwrite(buf.data(), 1, len, _file); return ptr; }
Running Doom3BFG.exe now produces a file called doom3_journal.txt. This journal records every single malloc and free from startup to shut down. It looks like this:
a 2048 0000023101F264A0 15888 542200 a 1280 0000023101F28020 15888 1098100 a 2560 0000023101F298A0 15888 1130500 f 0000023101F28020 15888 1142000 a 3840 0000023101F2A300 15888 1146900 f 0000023101F298A0 15888 1154900 a 1280 0000023101F28020 15888 1171200 a 2560 0000023101F298A0 15888 1189500 f 0000023101F28020 15888 1191900 a 3840 0000023101F2B260 15888 1202200 f 0000023101F298A0 15888 1207900
All content for the rest of this post is derived from the same journal. It's a 420 megabyte file containing over 11,000,000 lines. Roughly 5.5 million mallocs and 5.5 million frees. It leaks 7 megabytes from 8473 mallocs, tsk tsk.
The journal covers 7 minutes of game time. I entered the main menu, selected a level, played, died, reloaded, died again, quit to main menu, and quit to desktop. I did this a few times and each run produced very similar journals.
Replaying the Journal
Next, we need to write code to load and replay the journal. To do this I created a new C++ project called MallocMicrobench. The code can be summarized as:
std::vector<Entry> journal = ParseJournal("doom3_journal.txt"); for (auto& entry : journal) { // Spin until journal time while (ReplayClock::now() < entry.timepoint) {} if (entry.op == Alloc) { // Measure malloc auto allocStart = RdtscClock::now(); void* ptr = ::malloc(entry.size); auto allocTime = RdtscClock::now() - allocStart; } else { // Measure free auto freeStart = RdtscClock::now(); ::free(entry.ptr); auto freeTime = RdtscClock::now() - freeStart; } }
This snippet excludes configuration and bookkeeping. The basic idea is very simple.
Running my journal through the new replay system produces the following output:
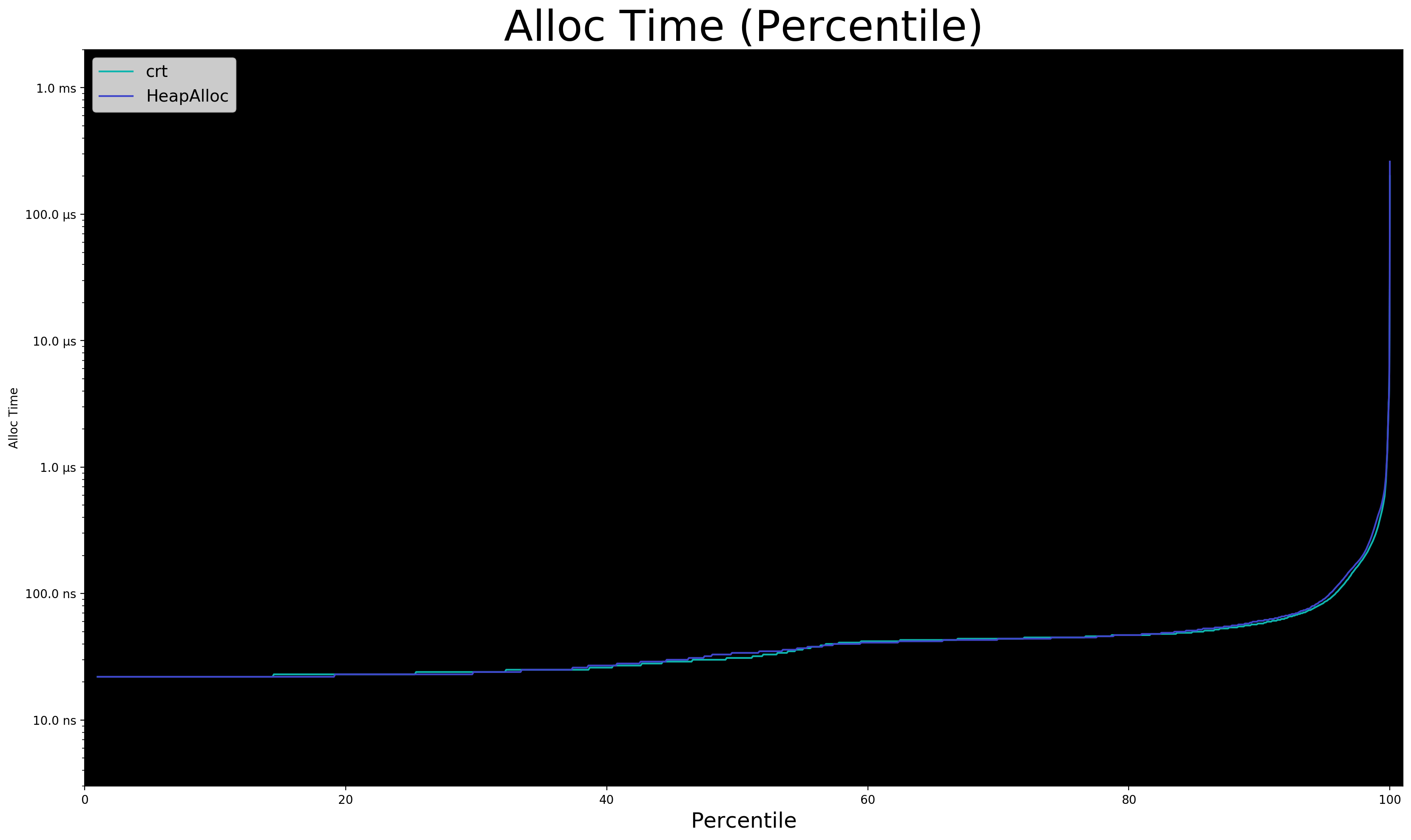
Parsing log file: c:/temp/doom3_journal.txt Running Replay == Replay Results == Number of Mallocs: 5531709 Number of Frees: 5523236 Total Allocation: 2.47 gigabytes Max Live Bytes: 330 megabytes Average Allocation: 480 bytes Median Allocation: 64 bytes Average Malloc Time: 57 nanoseconds Num Leaked Bytes: 7 megabytes Alloc Time Best: 21 nanoseconds p1: 22 nanoseconds p10: 22 nanoseconds p25: 23 nanoseconds p50: 31 nanoseconds p75: 45 nanoseconds p90: 58 nanoseconds p95: 86 nanoseconds p98: 192 nanoseconds p99: 316 nanoseconds p99.9: 3.07 microseconds p99.99: 25.75 microseconds p99.999: 95.01 microseconds Worst: 200.74 microseconds
Interesting! Average malloc time is 57 nanoseconds. That's decent. However p99.9 time (1 in 1000) is 2.67 microseconds. That's not great. Worst case is a whopping 200 microseconds, ouch!
What does this mean for hitting 144Hz? Honestly, I don't know. There's a ton of variance. Are the slow allocations because of infrequent but large allocations? Do slow allocs occur only during a loading screen or also in the middle of gameplay? Are outliers due to OS context switches? We don't have enough information.
Note: Evidence indicates that on Windows the C Runtime (CRT) malloc is a thin wrapper around HeapAlloc. This post will stick with the terminology malloc. All replays were run in Release mode from a Windows console.
{kind=link}
{kind=link}
Visualizing the Replay
We need to graph our replay data to make better sense of it.
First, I took doom3_journal.txt, ran a replay, and produced a new doom3_replayreport.csv. This replay report contains replay timestamps and profiler time for malloc and free. It looks like this:
replayAllocTimestamp,allocTime,allocSize,replayFreeTimestamp,freeTime 661500,375,2048,0,0 881700,531,1280,912000,254 911600,268,2560,935400,343 917500,261,3840,0,0 935800,153,1280,961800,101 961600,206,2560,962700,146 962000,248,3840,0,0 984500,447,3760,432968726000,397 993400,18980,3760,432968728400,758 1012500,1354,3760,432968729200,133 1013900,1365,3760,432968842900,161
To graph this data I used Python's matplotlib.
After several failed experiments I landed on scatterplots. This looked great. Unfortunately, Python is a miserably slow language so rendering 11 million points took over 45 seconds. Yikes!
A kind Twitter user pointed me towards a matplotlib extension called mpl-scatter-density. This worked phenomenally well and turned 45 seconds into 3 seconds. My biggest bottleneck is now csv parsing.
New tools in hand I produced this:
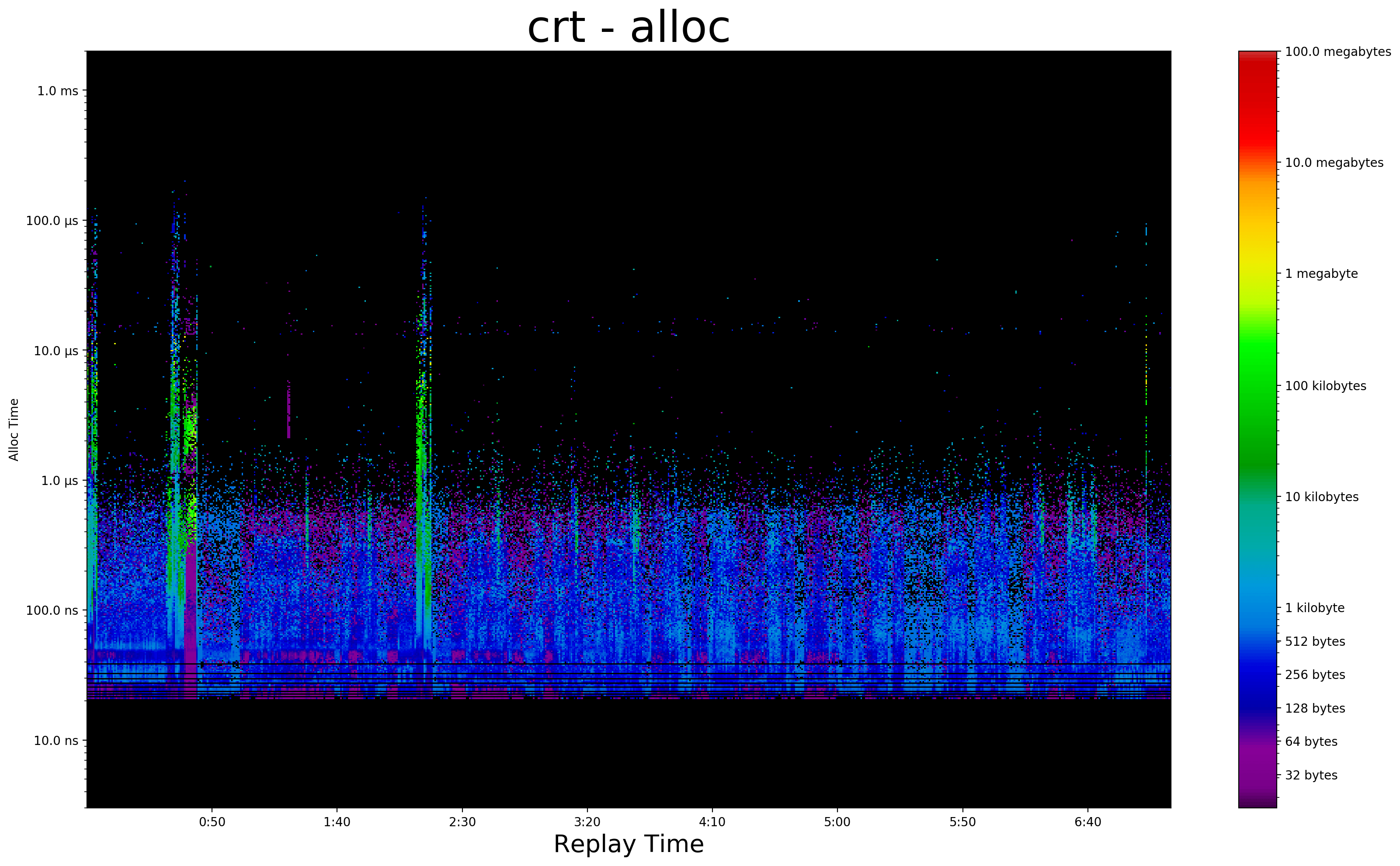
Data visualization is story telling. This story has a lot going on. Let's break it down.
- each pixel is one
mallocorfree - x-axis is replay time
- y-axis is
malloc/freetime, in logarithmic scale - pixel color is alloc size
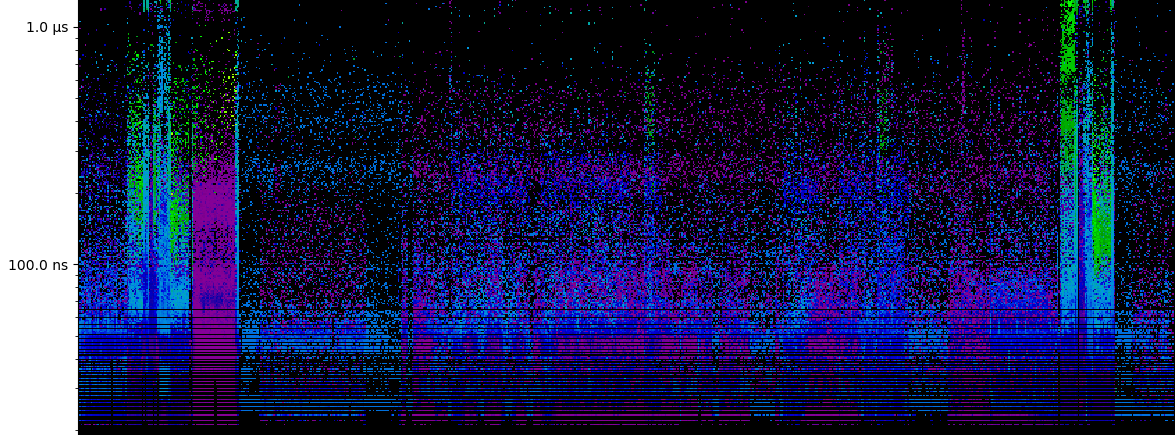
There are expensive mallocs at the very start when the game first boots. At ~30 seconds there are large and expensive mallocs as the level loads. There are similar allocations when I die and reload at 2 minutes.
During actual gameplay the vast majority of allocations take between 21 nanoseconds and 700 nanoseconds. Not amazing. Unfortunately there are numerous mallocs sprinkled between 1 and 20 microseconds. Even worse, those expensive mallocs are as small as just 16 bytes!
Here's a zoom shot that covers the first gameplay segment.
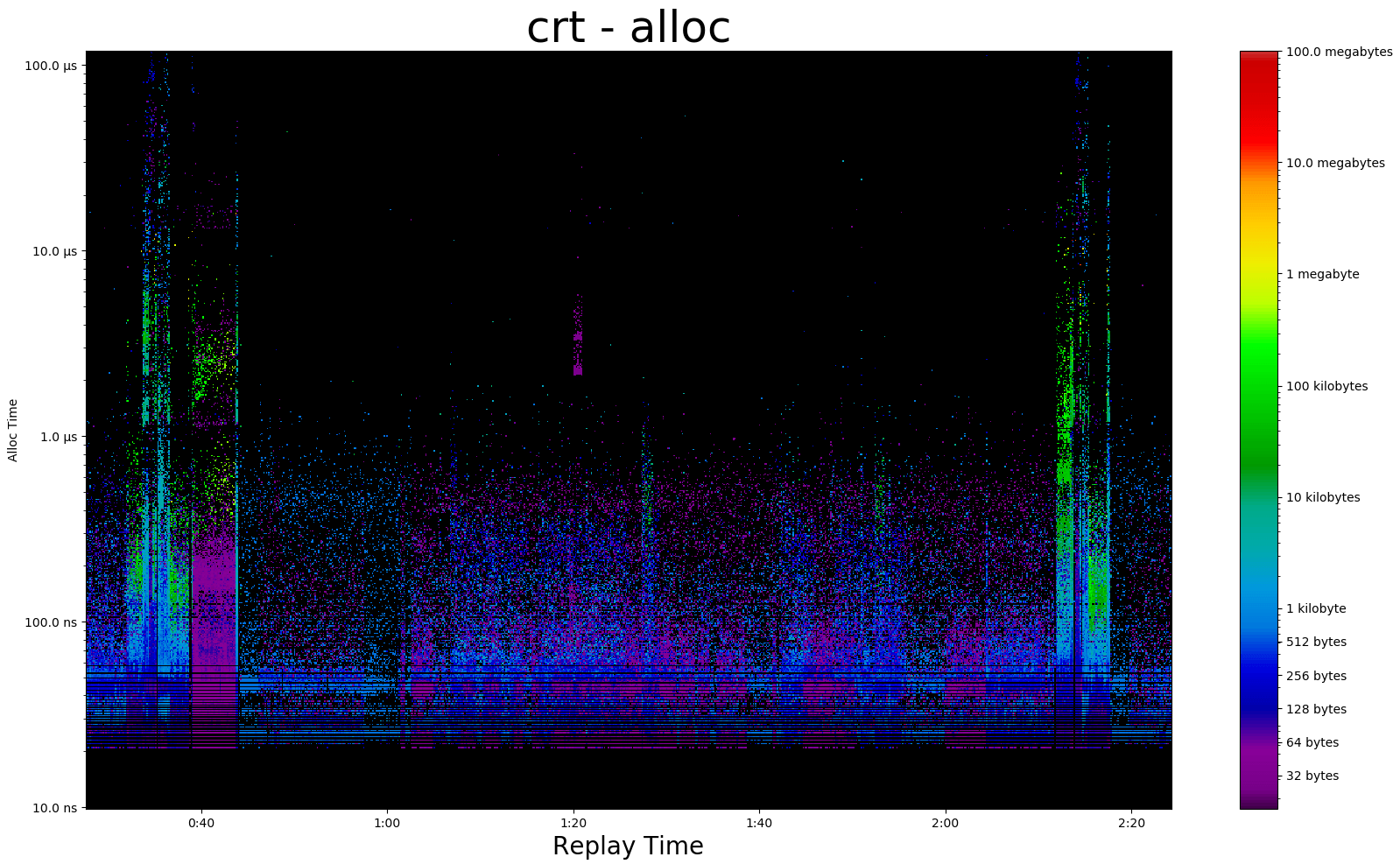
All images in this post are clickable if you'd like to view full-res.
Initial Takeaways
What can we take away from this? A few things.
- C Runtime (CRT)
mallocis highly variable p90mallocis ~60 nanosecondsp99.99mallocis ~25 microseconds- Worst case for gameplay is ~100 microseconds
Is this good or bad? It sure feels bad. The inconsistency is frustrating. However it's important to note that my gameplay ran a rock solid 60fps!
Worst degenerate case is my computer catches fire. Thus far my computer has not caught fire. Nor has malloc frozen my computer for seconds. Worst case for gamplay seems to be on the order of a few hundred microseconds.
I'm going to make a bold claim:
You can call malloc and still hit real-time framerates.
I believe this is true even if you're writing audio code that needs to compute a buffer every 4 milliseconds.
The problem isn't malloc per se. The problem is if you call malloc once then you probably call it more than once. It's death by a thousand cuts. It adds up fast and once you have 1,000 calls to malloc it's excruciatingly difficult to unwind.
Page Commit
Astute readers may have noticed we aren't writing to memory. This could have serious performance implications! The previous snippet was overly simplified, sorry.
I ran my replay with three options.
malloconlymalloc+ write1byte every4096malloc+memset
The code looks like this:
auto mallocStart = RdtscClock::now();
auto ptr = Allocator::alloc(entry.allocSize);
#if WRITE_STRATEGY == 2
for (size_t i = 0; i < allocSize; i += 4096) {
*reinterpret_cast<uint8_t*>(ptr) = 42;
}
#elif WRITE_STRATEGY == 3
std::memset(ptr, 42, allocSize);
#endif
auto mallocEnd = RdtscClock::now();
It produces the following result:
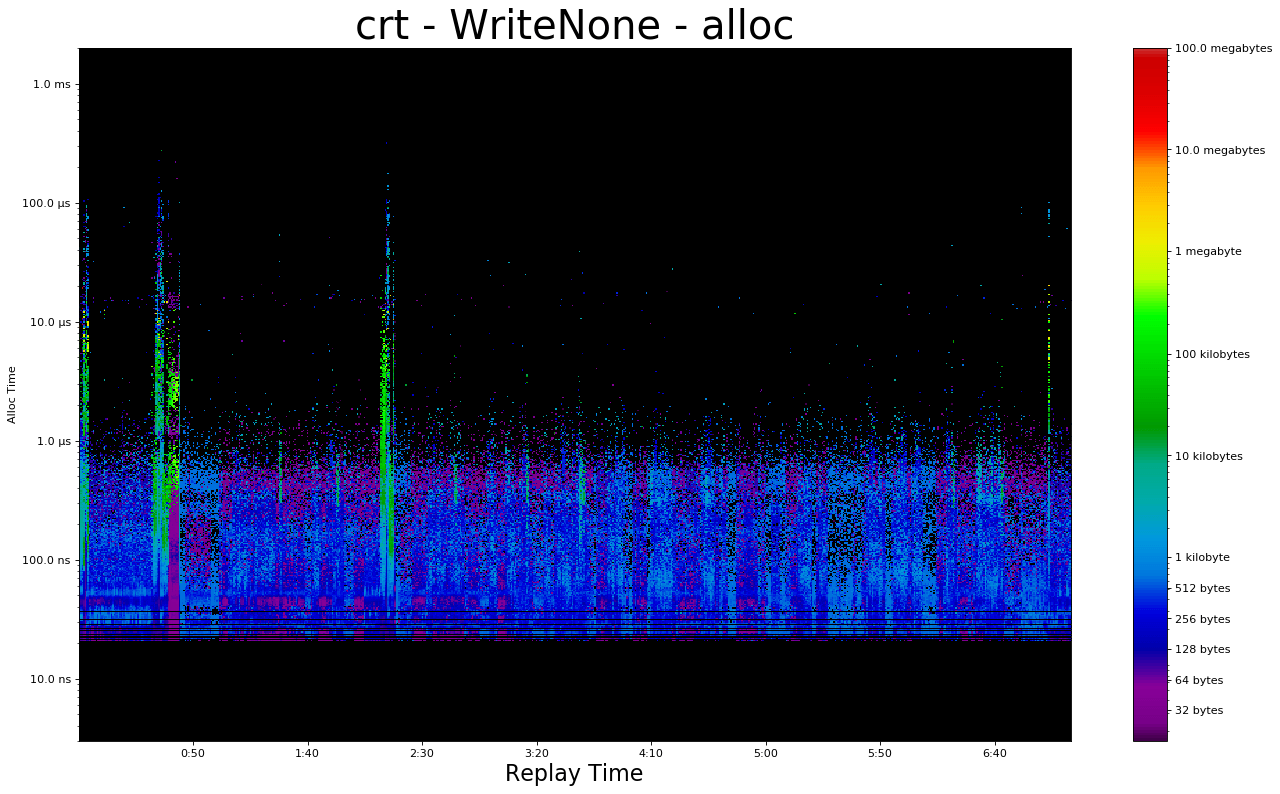
On Windows the difference between "write none" and "write byte" is not tremendous. Twitter friends tell me the difference will be large on Linux, but I do not know. As a game dev I am moderately allergic to Linux.
Option 3 is just measuring memset. That's a whole separate conversation.
None of these choices are a perfect match for real program behavior. This post uses option 2, "write byte per 4096" as default behavior. It's a compromise.
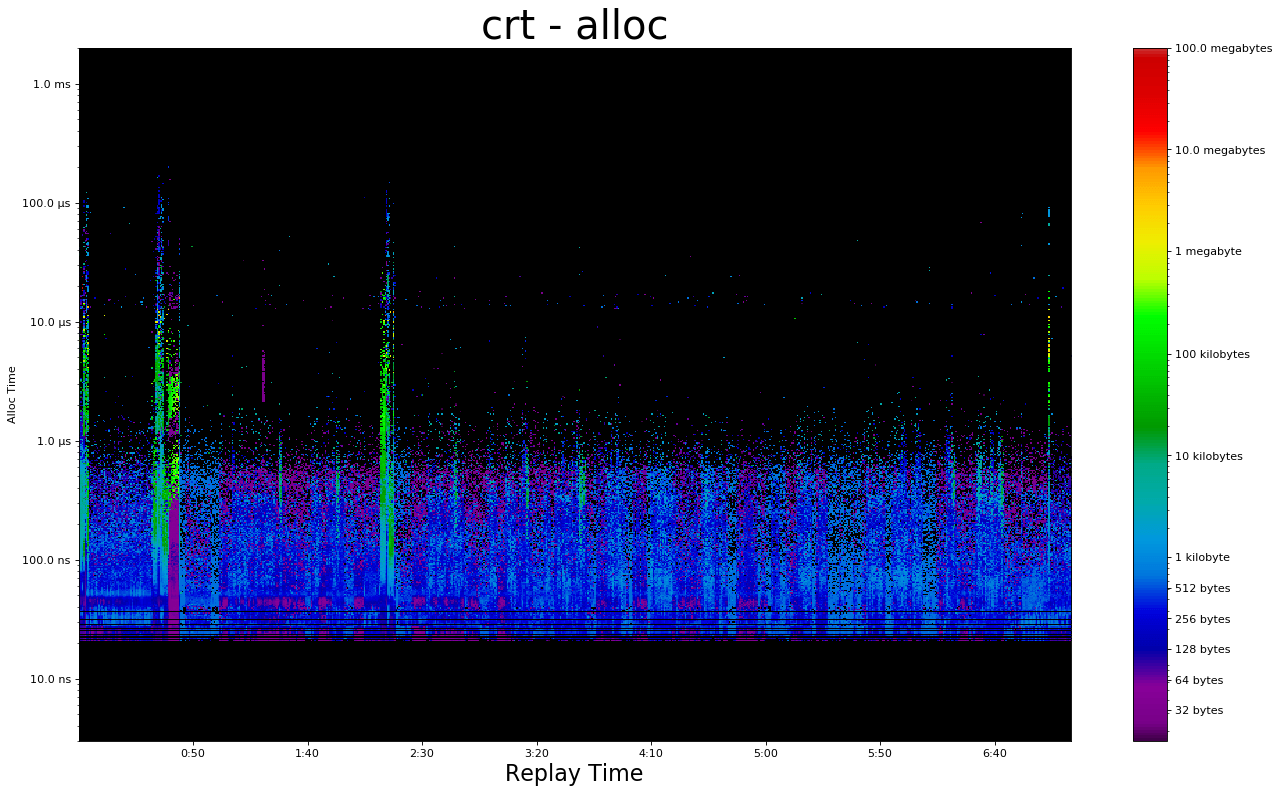
Replay Speed
It is tempting to execute a replay at an accelerated pace. Waiting 7 minutes for every replay test is time consuming and annoying.
My MallocMicrbench program supports scaling replay speed by an arbitrary rate. This is critical for testing.
Unfortunately it appears that running the replay faster has a very tangible impact on performance. Therefore this post will take the time to replay at 1x. Bah hum bug.
Replacement Allocators
We're not done yet.
Testing thus far has used CRT malloc. Now that we have a memory journal and replay system we can replay the exact sequence of allocations in different allocators.
I chose five allocators to compare.
- dlmalloc – previously popular
- jemaloc – industrial strength, tuned for long running servers
- mimalloc – general purpose allocator by Microsoft
- rpmalloc – lockfree GPA by a now Epic Games employee
- tlsf – pool allocator used in some games
Numerous other libraries were considered. Most were excluded because compiling them on Windows required too much effort. I'm looking at you TCMalloc.
The goal today is not to determine which one is "best". Remember, it depends! We just want to build some more plots and see if we find anything interesting. This is an exploration.
Allocator Comparison
Let's get right to it. Here are the chosen allocators. All performed the exact same allocations, in the same order, over the same 7 minutes.
Play around with it. Compare allocators. Compare malloc vs free.
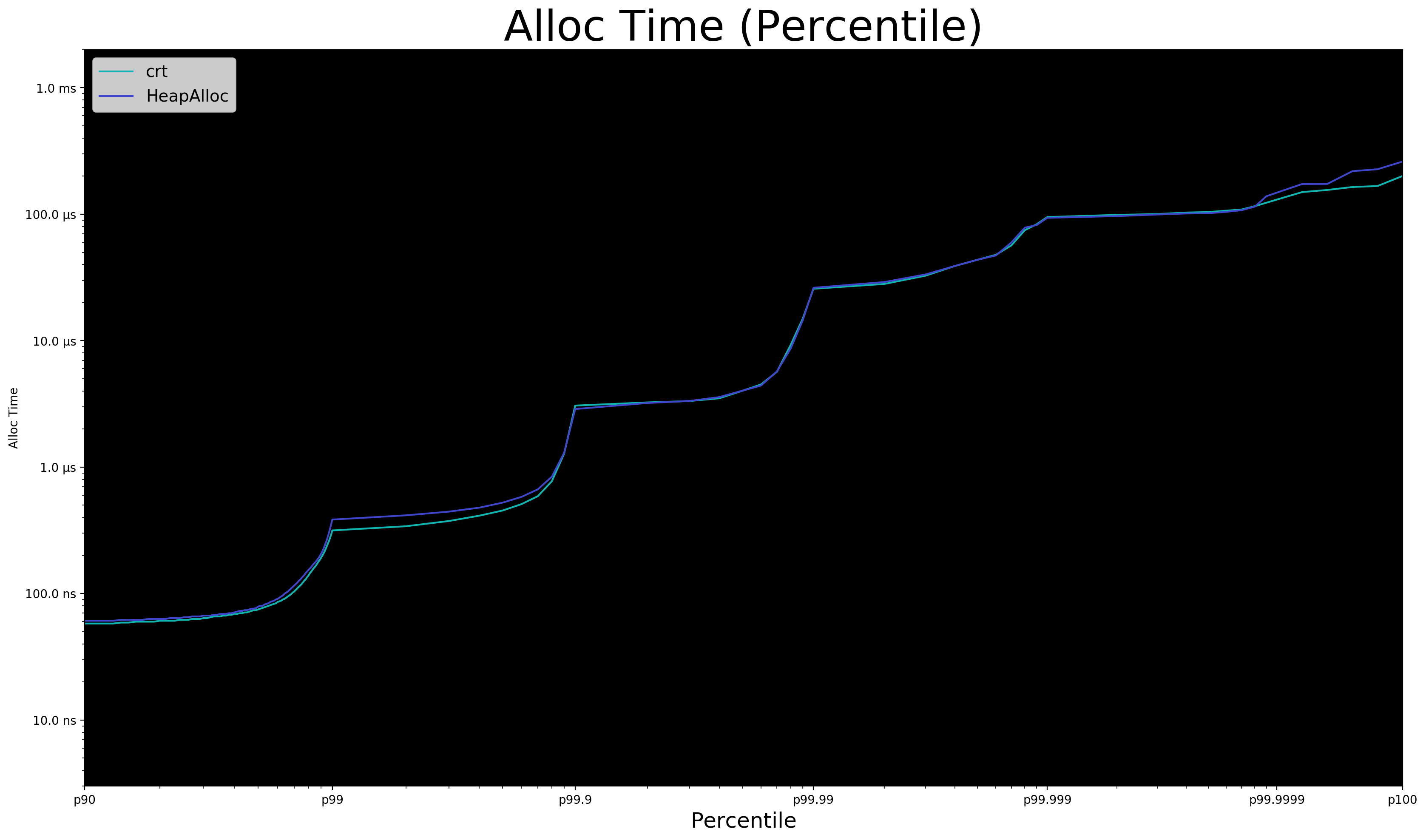
I'm happy with my scatterplots. Unfortunately rendering 5.5 million pixels on a 1200px wide plot has a lot of overlap. It obfuscates important information such as p50 and p95 time. It's difficult to build a plot that shows both density and outliers.
To help, here's a second plot that showcases percentile time. (The >p90 plot was extremely tricky to make and I'm rather proud of the result.)
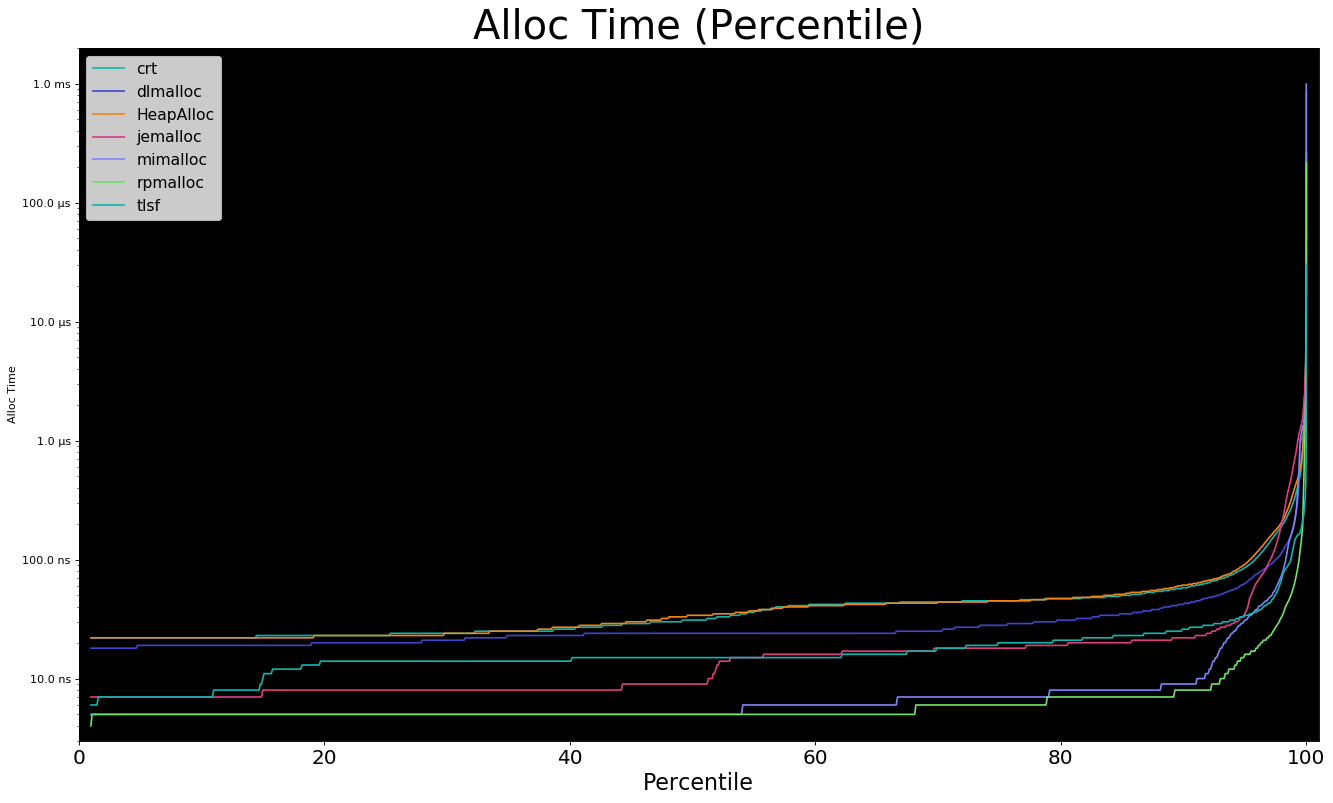
Here are some observations.
- CRT is quite bad
- ⚠️
dlmallocandtlsfare old and single-threaded jemalloc,mimalloc, andrpmallocare "modern allocators"- Modern allocators:
- Are designed for multi-threading
p50mallocin under 10 nanosecondsp95mallocin ~25 nanoseconds- Worst 0.1%: 1 to 50 microseconds
- Absolute Worst: ~500 microseconds
freeis comparable tomalloc- Maybe slightly faster on average
- Maybe somewhat worse on worst case
- Some cost is likely deferred and not measured
tlsfshines in worst case- Requires pre-allocating pool and is single-threaded.
- Trade-offs!
What did you take away from the data?
Revisting Game Audio
This all started because of a blog post about game audio. So, can you call malloc in a latency sensitive game audio library?
I'm going to be a heretic and say yes. You shouldn't! Pre-allocating a pool of fixed size buffers is super easy. Do that instead. But you totally can call malloc and your computer won't catch fire and you won't glitch your device.
Latency vs Reliability
This touches on a topic near and dear to my heart – latency. What we're really talking about is latency vs reliability.
Game audio systems work on sample buffers that are on the order of a few milliseconds. If you fail to deliver a buffer in time there is an ear piercing screech.
This is easy to protect against. Queue your buffers! If you need to deliver 4ms buffers then keep a full 4ms buffer in queue. This increases latency by 4ms but may increase reliability to 100%.
How much latency is too much? A Reddit discussion contained a rule of thumb I like:
- 2ms - works for pro audio
- 20ms - works for gaming
- 200ms - works for music
- 2000ms - works for streaming
One of my favorite YouTube channels measured end-to-end latency for game audio. Highly optimized shooters had audio latency ranging from 75 to a whopping 150 milliseconds.
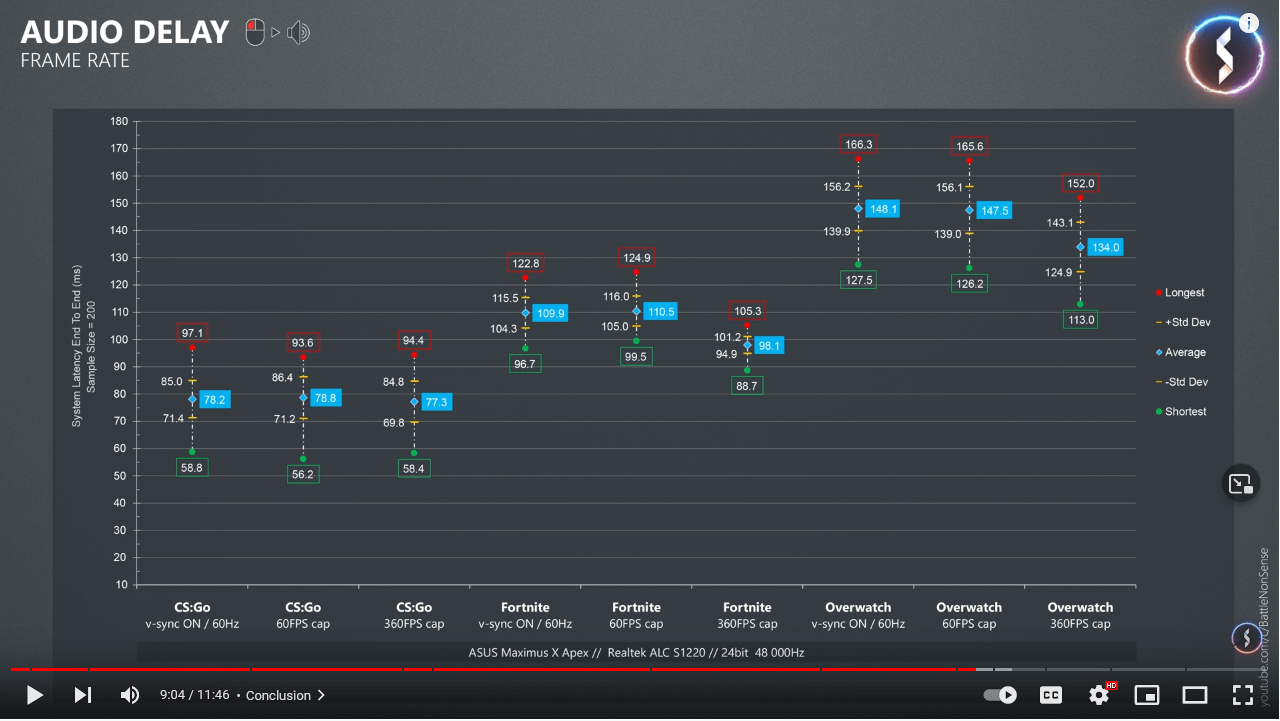
Source: Battle(non)sense, YouTube
Game audio engines should not add latency for no reason. However, if a user is experiencing 100ms latency then architecting complex systems or spending weeks to save microseconds is not the best use of your time, imho.
Ultimately the ONLY thing that matters is hitting your performance target. Pick a reasonable target and do what it takes to hit it. Doom 3 hits 60fps in debug and calls malloc all over the place. :)
Limitations
There are a lot of limitations to this post.
- Only ran on high-end desktop
- Only ran on Windows
- Embedded / smartphones / consoles are different worlds
- Doom 3 originally shipped in 2004
- Peak live usage of just 330 megabytes
- Only allocated 2.47 gigabytes total
- Doom 3 is an extremely well optimized game!
- Only 2.9% of
freescross threads - 7 minutes isn't very long
- Tested just a single application
- Micro-benchmarking isn't the real world
mallocandfreehave unmeasured, deferred costs- My code may have bugs
- Data viz is hard
- Context switches are not captured
The list goes on and on. If you have a snarky gotcha you're not wrong. Add it to the list.
It's also worth noting the many things this post does not even attempt to measure.
- Bookkeeping overhead
- Cache overhead
- Fragmentation
- and more
Conclusion
I nerd sniped myself with a question: what is the worst-case performance for malloc on a modern machine in practice?
I've set myself up for failure. Anything I say here will be nitpicked. :(
Here's my handwavey, napkin math, rule of thumb, rough guidelines:
mallocPerformace- Minimum: ~5 nanoseconds
- Median: ~25 nanoseconds
- Worst 0.1%: 1 to 50 microseconds
- Absolute Worst: ~500 microseconds
There's a famous list of latency numbers called Numbers Every Programmer Should Know. It inspired me to write a blog post titled Memory Bandwidth NapkinMath. This post is a similar style, but even more handwavey because malloc performance is so variable.
I had fun writing this. I learned things. I will personally keep these guidelines in mind when I write code.
Thanks for reading.
Future Work
I spent way too much time on this post. I don't have current plans to spend more.
It would be interesting to run some modern games through my data viz pipeline. Doom 3 is 18 years old. I think a Battle Royale game would be fascinating because they involve level streaming, user customization, and capped match length. My e-mail address is easy to find. :)